Abstract
Streaming video is fundamentally time-causal: frames arrive sequentially, the “present” is seen once, the “past” accumulates into memory, and the “future” is unavailable. However, current Video-LLMs are often time-agnostic, treating videos as an unordered bag of evidence. This leads to two failures in streaming: Temporal Order Ambiguity (attending to semantically similar but temporally mismatched evidence) and Past–Current Focus Blindness (indiscriminate use of ever-growing memory).
We propose WeaveTime, a simple and model-agnostic framework that first teaches order and then uses order: (1) SOPE (Streaming Order Perception Enhancement) trains order-aware representations via a lightweight Temporal Reconstruction objective, and (2) PCDF-Cache (Past–Current Dynamic Focus Cache) performs uncertainty-triggered, coarse-to-fine temporal retrieval, expanding history only when needed. Plugged into strong backbones (e.g., Qwen2-VL-7B and LLaVA-OV-7B) without architectural changes, WeaveTime improves streaming performance while keeping latency/memory stable.
Overview


Motivation: Why Time-Agnosticism Hurts Streaming
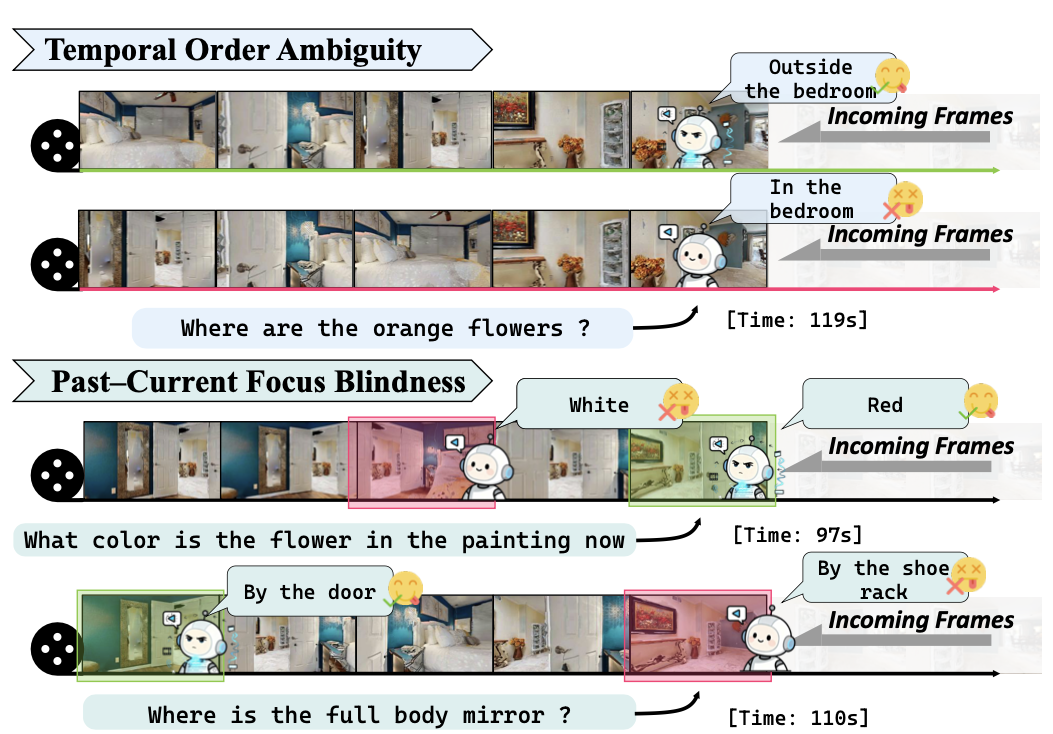
In offline video QA, a model can freely attend over the entire clip. In streaming, it cannot: the future is hidden, and the past grows without bound. If a Video-LLM does not explicitly model temporal order, two issues show up frequently:
- Temporal Order Ambiguity: it uses evidence from the wrong time (semantically similar frames but mismatched order).
- Past–Current Focus Blindness: it either over-relies on past memory (even when the answer is in the current frame) or fixates on the present (even when historical context is required).
Method
WeaveTime follows a simple recipe:
1) SOPE: Streaming Order Perception Enhancement (Temporal Reconstruction)
We add a lightweight Temporal Reconstruction (TR) objective to instill order-aware representations with minimal fine-tuning. In practice, this can be implemented as an “order reasoning” sub-question that is appended before the original QA query, so the LLM can reuse intermediate computations.
2) PCDF-Cache: Past–Current Dynamic Focus Cache
After order perception is established, PCDF-Cache enforces a “look now, recall if needed” principle:
- Use only the current context when the model is confident.
- When uncertainty increases (e.g., higher entropy), trigger coarse-to-fine retrieval to expand and narrow the temporal search over the past.
This yields efficient context expansion aligned to the query’s needs instead of rescanning the full history every step.
Contributions (from the paper)
- Diagnose Time-Agnosticism in current Video-LLMs and show that disrupting temporal order leads to limited degradation, suggesting reliance on spatiotemporal shortcuts rather than causal reasoning.
- Propose WeaveTime, a Video-LLM-agnostic, plug-and-play framework for streaming VQA that does not require specialized streaming data.
- Introduce SOPE via a lightweight Temporal Reconstruction auxiliary task to instill order-aware representations with minimal fine-tuning.
- Design PCDF-Cache, an uncertainty-aware, coarse-to-fine temporal retrieval mechanism for selective and efficient use of history under time-causal constraints.
- Demonstrate consistent gains across representative streaming benchmarks (e.g., OVO-Bench and Streaming-Bench) on strong backbones (e.g., Qwen2-VL and LLaVA-OV).
Experiments (from the paper)
WeaveTime is designed to be plug-and-play: it can be added on top of existing Video-LLM backbones (e.g., Qwen2-VL-7B and LLaVA-OV-7B) without architectural changes, and is evaluated on representative streaming benchmarks including OVO-Bench and Streaming-Bench.
TODO
- add abstract
- add method overview
- add arXiv link
- add code link
BibTeX
@article{zhang2026weavetime,
title={WeaveTime: Stream from Earlier Frames into Emergent Memory in VideoLLMs},
author={Zhang, Yulin and Shi, Cheng and Yang, Sibei},
journal={arXiv preprint arXiv:2602.22142},
year={2026}
}